英伟达Llama 3.1数据合成教程:手把手教你优化模型!
Epoch AI上个月刚刚发文预言「数据墙」迫近,结果英伟达转头就甩出了340B开源巨兽Nemotron。
真实数据稀缺可能不再是问题了,Nemotron 9T token的预训练预料中,98%都是合成数据。
也许你还对合成数据存在顾虑,或者不知道如何应用LLM驱动数据生成。或许,英伟达的这篇博客可以提供答案。

原文地址:https://developer.nvidia.com/blog/creating-synthetic-data-using-llama-3-1-405b/?linkId=100000275486093
首先我们需要理解,用LLM合成数据的本质究竟是什么?
合成数据并不是「从无到有」地创造新信息,而是对现有信息进行转换,生成不同的变体。
实际上,合成数据在AI领域的应用已经有十多年的历程,比如物体检测或分类系统中曾经的数据增强技术。

那么,LLM带来了什么新变化呢?
从「需求端」来看,由于模型需要大量训练语料,合成数据的动机被大大增强。
而在「供给端」,生成式语言模型也为合成数据技术带来了质的改变。
用合成数据微调基座模型,可以更好地应用于实际场景。例如,在金融领域改进风险评估、在零售领域优化供应链、在电信领域提升客户服务,以及在医疗领域改善患者护理等等。
尤其是405B开源巨兽Llama 3.1最近正式上线,既可用于批处理和在线推理,也可以作为基座模型,进行特定领域的专门预训练或微调。
尤其是考虑到Llama 3.1有如此大的参数规模,加上丰富的15.6T token训练数据,非常适合用于数据生成。
这篇博客文章将介绍几个合成数据的生成与应用案例,并就其中一个进行深入探讨。
LLM合成数据如何应用于GenAI
要通过合成数据来微调模型,大致有两种方法——知识蒸馏(knowledge distillation)和自我改进(self-improvement)。
知识蒸馏是将大模型的能力转移到较小模型的过程,但不是简单地在同一个数据集上训练两个模型,因为较小模型很难学习到底层数据的准确表征。
在这种情况下,我们可以先让大模型完成任务,再使用这些数据指导小模型进行。
自我改进则是让同一个模型评判自己的推理过程,常被用于进一步磨练模型的能力。
让我们来看看如何实现这一目标。训练语言模型通常包括三个步骤:预训练、微调和对齐(alignment)。
预训练
预训练通常需要极其庞大的语料库,使模型了解语言的一般结构。
Llama 3.1、GPT-4这种通用LLM,一般需要互联网规模的数据。而特定领域的LLM(如几何学、放射学、电信行业等)则需要注入相关的领域信息,这个过程被称为领域自适应预训练(Domain Adaptive Pretraining,DAPT)。
除了要贴近相关领域,另一种在预训练阶段使用合成数据的例子当属Phi-1.5模型,目的是注入逻辑推理能力。
微调
掌握了语言的一般结构后,下一步就是微调,让模型更好地遵循指令、完成特定任务。
比如,要让模型提高逻辑推理能力、实现更好的代码生成和函数调用,或者提升阅读理解类任务的表现,都可以通过微调来实现。
Self-Instruct、WizardCoder、Alpaca等模型都通过创建特定领域的数据并进行微调,来定向提升模型能力。
对齐
最后,我们希望确保模型响应的风格和语气与用户期望一致,例如听起来像对话、具有适当的详细程度、复杂性、一致性等。
可以创建一个包含指令模型(instruct model)和奖励模型(reward model)的流水线来实现这个需求。
先让模型对同一问题创建多个响应,然后让奖励模型对这些相应的质量进行反馈。这种方法属于从AI反馈中进行强化学习(Reinforcement Learning from AI Feedback, RLAIF)。
改进其他模型和系统除了改善语言模型本身,合成数据还可以应用于LLM邻接模型(LLM-adjacent model)以及LLM驱动的流水线。
最经典的例子就是检索增强生成(Retrieval Augmented Generation,RAG),先用嵌入模型来检索相关信息,再让语言模型生成最终答案。
在这个过程中,我们可以使用LLM来解析底层文档和合成数据,从而评估并微调嵌入模型。
类似于RAG,任何智能体(Agentic)流水线都可以被评估,其组件模型也可以被微调,实现方式就是用LLM驱动的智能体来构建模拟。
这些模拟还可以用于研究行为模式,此外,也可以在LLM中设定特定角色,以针对特定任务进行大规模数据生成。
使用合成数据评估RAG
为了更好地理解上述讨论,我们来思考一个基本的流程,应用于一个具体的用例——为检索过程生成评估数据。
下述流程的实现代码已经上传至GitHub。

项目地址:https://github.com/NVIDIA/NeMo-Curator/tree/main/tutorials/synthetic-retrieval-evaluation
要创建用于评估检索流程的数据,主要面临以下2个挑战:
多样性:问题不应只关注信息的单一方面或仅包含提取性问题复杂性:生成的问题应需要一些推理或多个证据来回答我们将重点关注多样性,但为了探索复杂性角度——关键是找到具有重叠信息点的内容块。找到重叠信息的几种方法包括计算句子级语义的Jaccard相似度,并利用长上下文模型找到同一文档的不同块之间的关联。
多样性源自不同的视角,比如考虑如下文本:

对于同一篇文档,金融分析师可能对两家公司合并前后的财务状况感兴趣,法律专家可能关注公司面临的来自FTC、欧盟和其他方的法律审查,记者则希望了解事实要点。
所有这些都是有效的视角和用户角色。由于他们以不同的视角看待相同的信息,因此评估流程也需要适应这些视角。
因此,让我们设计一个评估流程,该流程以文档和用户角色作为输入,并以符合角色的语气输出问题。

图1. 三步流程的概述:生成用于评估检索过程的合成数据
如图1所示,这个评估流程有三个主要步骤。
步骤1:生成所有可能的问题
这些问题都是用户角色可能感兴趣的。
步骤2:筛选出相关的问题
从生成的问题中筛选出最相关和有价值的问题。
步骤3:引入用户角色的写作风格
将筛选出的问题转换为符合用户角色写作风格的形式。
通过这三个步骤,可以确保不同用户角色获得他们所需的信息,并以他们熟悉的方式呈现。
步骤1:生成问题在生成问题之前,我们需要先读取文档并将其分成若干块(chunk)。
然后,让LLM从给定的文本块中,为每个用户角色提取感兴趣的点。
所谓的「用户角色」(persona),实际上就是对潜在用户的描述,比如:

由于多个用户角色可能有相似的兴趣点,因此需要使用嵌入模型来进行语义去重,从而为每个角色映射出段落中不同的相关信息。
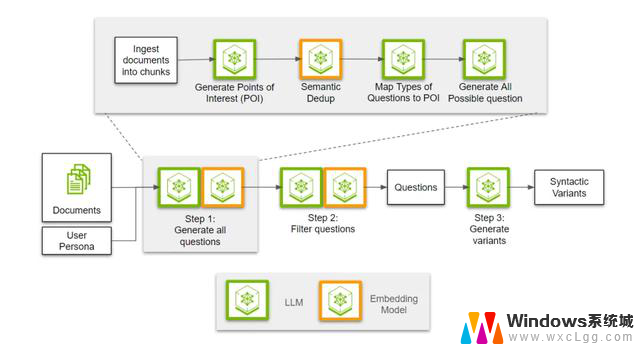
多样性的另一个方面是问题类型。
我们需要提出各种类型的问题,如提取性、抽象性、比较性的问题,而不仅仅是简单的「如何/什么」问题。因此,下一步是根据段落中的信息,确定每个兴趣点适用的问题类型。
最后,利用文本块-兴趣点-问题类型的三元组,生成所有可能的问题。通过用户角色和问题类型,开发人员可以将生成的问题引导到用户会问的类型上。
 步骤2:过滤问题
步骤2:过滤问题生成问题之后,下一步就是过滤并提取最有用的子集。首先,我们需要对所有生成的问题进行去重,因为不同的兴趣点可能会利用相邻的信息点,导致问题重叠。
接下来,我们使用LLM来判断问题与段落的相关性,确保这些问题能够完全通过段落中的信息回答。然后,我们将所有相关问题重写为对话语气。最后,我们会进行另一次过滤,分类并剔除那些可能过于笼统的问题。
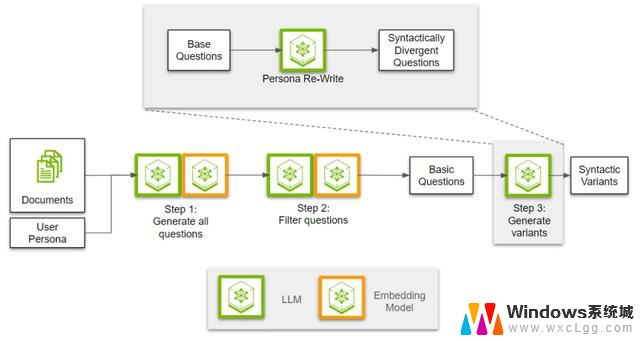
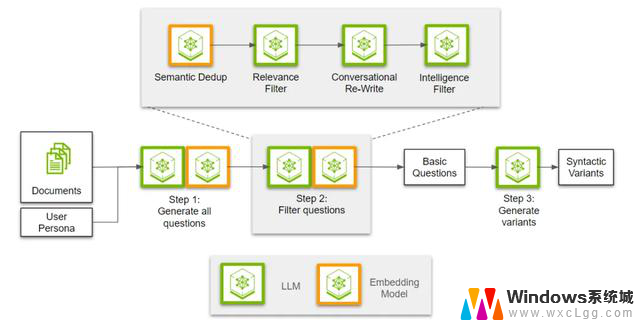 步骤3:注入用户角色风格
步骤3:注入用户角色风格在前两步中,我们创建并筛选了多样化的问题。最后一步是将用户角色的写作风格融入到问题中。
使用LLM,我们首先根据给定的用户角色描述来制定写作风格。然后,基于这些写作风格重新改写问题。
比如,可以这样描述用户角色的写作风格:

在这个三步流程结束后,我们得到了如下问题:
鉴于现行的监管框架,拟议的合并还需要遵守哪些额外的政策指令,才能获得相关部门的批准?SolarPower和GreenTech合并的哪些具体方面目前正在接受相关监管部门的审查?如果在大笔买断之后,GreenTech的研发中心保持单飞状态,那些天才会被炒鱿鱼吗?可以看出,前两个问题很像Padma的语气,而第三个问题似乎是Aaron会问的。
这些问题各自包含了真实标签,对应特定的文本块,因此不仅限于这一个用例,可以用于评估各种检索流程。
英伟达Llama 3.1数据合成教程:手把手教你优化模型!相关教程
-
 三季度数据中心业务贡献过半 AMD如何追赶英伟达?数据中心业务竞争对手分析
三季度数据中心业务贡献过半 AMD如何追赶英伟达?数据中心业务竞争对手分析2024-10-31
-
 英伟达驱动更新:永劫无间和战锤:末世鼠疫2DLSS 3优化计划
英伟达驱动更新:永劫无间和战锤:末世鼠疫2DLSS 3优化计划2023-10-17
-
 英伟达显卡和 AMD 显卡的比较分析:哪个更适合你?
英伟达显卡和 AMD 显卡的比较分析:哪个更适合你?2024-03-08
-
 美光重返中国,英伟达50亿对华订单受挫,美国招数有何变化
美光重返中国,英伟达50亿对华订单受挫,美国招数有何变化2023-11-06
-
 英伟达望超越英特尔、三星,成为行业第一
英伟达望超越英特尔、三星,成为行业第一2023-12-28
-
 英伟达联手基因泰克,芯片巨头助力AI制药的关键在哪里?
英伟达联手基因泰克,芯片巨头助力AI制药的关键在哪里?2023-11-24
- 英伟达问鼎全球市值榜首,黄仁勋揭秘“超能力”助成功
- 英伟达,大消息:英伟达发布重要消息,引发行业关注
- 英伟达推合规版RTX 4090D显卡,规格小幅下降,性能仍强劲
- 美国商务部限制中国获得先进芯片,英伟达成为焦点
- 微星GeForce RTX 5060Ti 16G硬派师评测:适合ITX小机箱的无光百搭显卡
- 影驰GeForce RTX 5060 Ti 金属大师黑金版MAX OC显卡开箱:2K光追游戏好手必备
- 微软开发出一种可在CPU上运行的超高效AI模型,革新人工智能技术领域
- NVIDIA对一些中国客户隐瞒了美国新一轮芯片限制措施,行业内震惊!
- AMD苏姿丰:美国逐渐成为台湾供应链的关键一环
- 怎么样校验Win10 ISO的SHA1 如何验证MD5值?教你轻松验证Win10 ISO文件的完整性
微软资讯推荐
- 1 微星GeForce RTX 5060Ti 16G硬派师评测:适合ITX小机箱的无光百搭显卡
- 2 影驰GeForce RTX 5060 Ti 金属大师黑金版MAX OC显卡开箱:2K光追游戏好手必备
- 3 微软开发出一种可在CPU上运行的超高效AI模型,革新人工智能技术领域
- 4 NVIDIA对一些中国客户隐瞒了美国新一轮芯片限制措施,行业内震惊!
- 5 AMD苏姿丰:美国逐渐成为台湾供应链的关键一环
- 6 怎么样校验Win10 ISO的SHA1 如何验证MD5值?教你轻松验证Win10 ISO文件的完整性
- 7 科技巨头被指规避2780亿美元企业所得税,调查揭露苹果、微软等六大公司涉嫌避税风波
- 8 AMD首款2nm芯片EPYC“Venice”采用台积电N2节点制造,性能提升明显
- 9 如何激活Windows系统,轻松解决电脑激活问题-最全攻略
- 10 如何安全有效地进行CPU超频教程与技巧,轻松提升电脑性能
win10系统推荐
系统教程推荐
- 1 笔记本开机闪屏是什么原因,怎么解决 笔记本电脑频繁闪屏怎么办
- 2 win10怎么更改子网掩码 Win10更改子网掩码步骤
- 3 声卡为啥没有声音 win10声卡驱动正常但无法播放声音怎么办
- 4 固态硬盘装进去电脑没有显示怎么办 电脑新增固态硬盘无法显示怎么办
- 5 word如何加批注 Word如何插入批注
- 6 怎么让word显示两页并排 Word文档同屏显示两页
- 7 win11直接改文件后缀 win11文件后缀修改教程
- 8 win11怎么查看电脑的物理地址 电脑物理地址查询方法
- 9 switch手柄对应键盘键位 手柄按键对应键盘键位图
- 10 win11安装共享打印机提示0000709 win11共享打印机提示0000709问题解决方法