专家模型不要专家并行!微软开源MoE新路径,颠覆传统机器学习模式
【新智元导读】近日,来自微软的研究人员开源了使用全新方法训练的MoE大模型,不走寻常路,且编码和数学表现出色。
继Phi家族之后,微软又开源了新的混合专家大模型——GRIN MoE。
与Phi-3.5同样的个头(16 * 3.8B),却采用了截然不同的训练方法。
这个「不走寻常路」如果写个太长不看版,那就是两句话:

论文地址:https://arxiv.org/abs/2409.12136
当然了,上面两句话是小编说的。多少有点糙,文中细节,还请诸君继续阅读~
这年头,新来一个LLM,当然要先刷分了——
参数要少,效果要好,所以要在左上角:
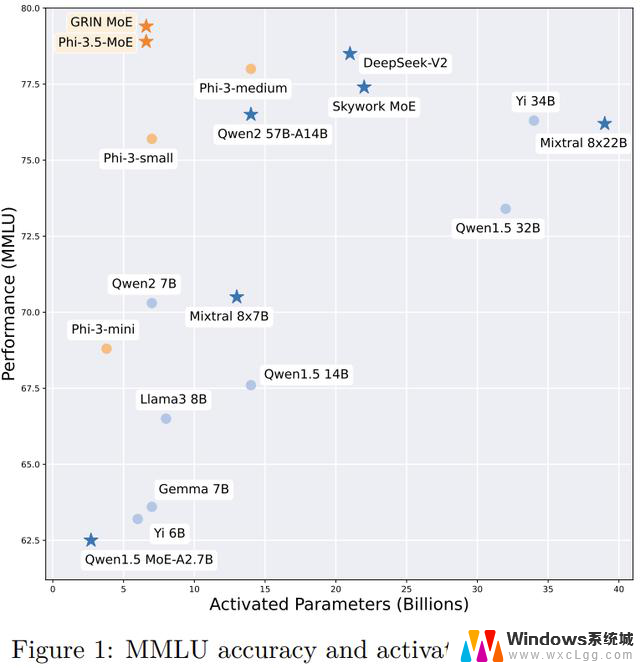
GRIN作为MoE架构,总参数量约42B,推理时激活的参数为6.6B,打同级别(7B)的非MoE模型是手拿把攥,甚至比14B的Phi-3还要略胜一筹。
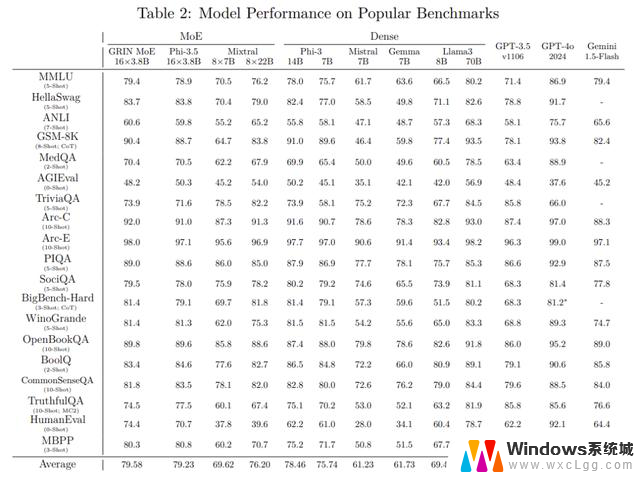
在上面的这份成绩单中,GRIN MoE表现优异,尤其是在编码和数学测试中。
比如,在衡量数学问题解决能力的GSM-8K中,GRIN MoE得分为90.4,而在编码任务基准HumanEval上拿到了74.4分。
在MMLU(大规模多任务语言理解)基准测试中GRIN得分为79.4,超过了同为MoE架构的Mixtral(70.5分),以及自家的Phi-3.5(78.9分)。
如果对比流行的商用模型,GPT-3.5表示感受到时代的力量,默默退出群聊。

开放权重:https://huggingface.co/microsoft/GRIN-MoE
demo:https://github.com/microsoft/GRIN-MoE
MoE全新训练路径
GRIN MoE由常规的Transformer块构成,采用分组查询注意力(GQA)和滑动窗口注意力来提高计算效率。
采用RoPE进行位置编码,以便在预训练后实现长上下文能力。

在MoE架构中,模型通过路由网络为每个输入token挑选适合的专家模块。对于有n个专家的网络,一个用于推理的MoE模块的输出为:
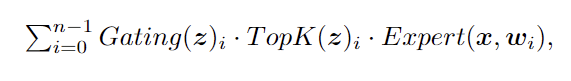
其中z = Router(x,r),本文中Router采用线性网络,Gating是门控函数(通常为softmax),Expert是FNN层。
MoE通过TopK函数进行专家分配,这个专家路由的过程是不可微的,所以反向传播的时候没法求导。
对此,传统的MoE训练将TopK视为常数,仅通过Gating来反向传播计算路由权重梯度,相当于用门控的梯度代替了路由的梯度。
这多少有点糙。
不可导怎么办恰好,本文一作之前有一篇工作(SparseMixer):

论文地址:https://arxiv.org/pdf/2310.00811
受到直通梯度估计器的启发,作者扩展了前作,提出了SparseMixer-v2。
作者首先将TopK函数替换为模型训练中离散变量的随机采样,然后应用heun’s third order method来近似专家路由梯度,并构建一个改进的反向传播,为专家路由给出数学上合理的梯度估计。

前作中,SparseMixer的有效性在神经机器翻译任务和ELECTRA语言模型训练中得到了证明。
而在GRIN MoE的开发过程中,SparseMixer-v2终于有机会大规模应用于自回归语言模型训练。
作者用2.5T token训练了两个16×0.9B MoE。其中一个遵循GRIN MoE中使用的相同方案,另一个用传统的GShard方法替换 SparseMixer-v2。
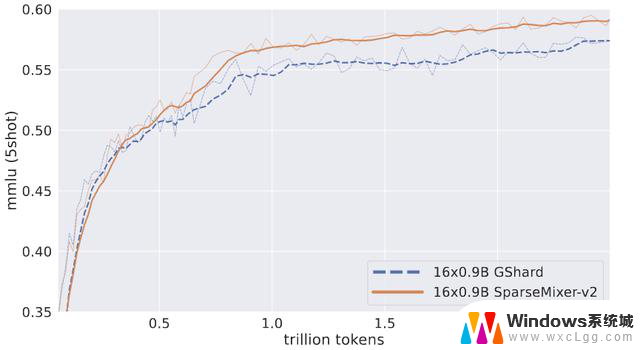
如上图所示,将SparseMixer-v2的性能提升推广到16×0.9B尺度的自回归语言模型训练。
在前0.5T token上GShard表现更好,但SparseMixer-v2在训练后期取得了更强的性能。
专家模型不要专家并行传统的MoE训练采用专家并行,简单理解就是把不同的专家分配到不同的显卡上。
一个明显的问题是负载不均衡,有的专家会分到更多的token,有的专家却很闲。
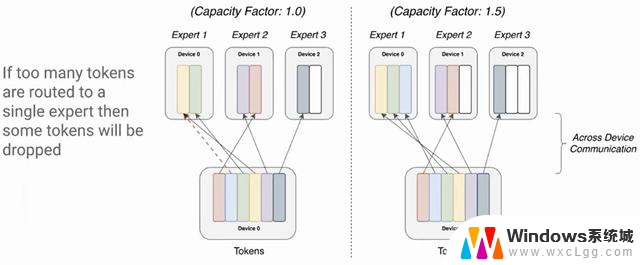
之前的做法是设定一个阈值,比如1000个token分给4个专家,每人应该是250,这时候每张卡就最多只算250个token,超过后直接丢弃(送到下一层)。
而在本文中,作者利用数据并行、pipeline并行和张量并行来训练GRIN MoE。
此外,对于没有专家并行性的MoE计算,作者发现Megablocks包非常有用,它的grouped_GEMM内核和包装器的性能更好。
应用这些新的工程化方法避免了专家并行,也就不用丢弃token了。
最终,与具有相同激活参数的密集模型相比,本文的方法实现了超过80%的训练效率提升。
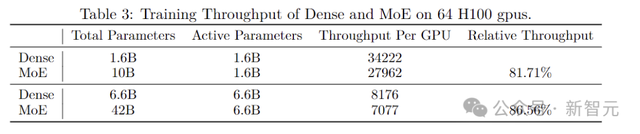
上表中,作者将两种不同大小的MoE模型与具有相同激活参数量的密集模型进行了比较,使用相同的硬件测量了它们的训练吞吐量。
尽管MoE总的参数量是密集模型的六倍多,但在实验中达到了超过80%的相对吞吐量,证实了使用GRIN MoE方法的模型具有显著的计算扩展潜力。
(PS:密集模型的吞吐量是在与MoE模型相同的并行度设置下测量的,这里的比较是为了研究密集激活网络(非MoE)和稀疏激活网络(MoE)的GPU内核效率)
此外,在扩大模型大小时,密集模型和MoE模型显示出相似的减速模式,比如6.6B密集模型的训练吞吐量大约比1.6B密集模型的训练吞吐量慢4.19倍(后者的参数少4倍)。同样,42B MoE模型的训练吞吐量比10B MoE 模型的训练吞吐量慢约3.96倍(对应参数少4.2倍)。
并行实验
在只使用pipeline并行的情况下,通过在GPU之间进一步划分不同层,可以将最大专家数量从16个扩展到32个。但是,如果再增加专家数量,则会导致单个层的参数过多,一个GPU就放不下了。
所以下一个维度采用张量并行。
专家并行在前向和后向计算中有两个all-to-all通信开销,而张量并行在前向和后向计算中有两个all-reduce通信开销。
相比之下all-reduce操作的延迟更高一点,但可以通过精心排布前向和反向的计算来overlap掉一部分开销。
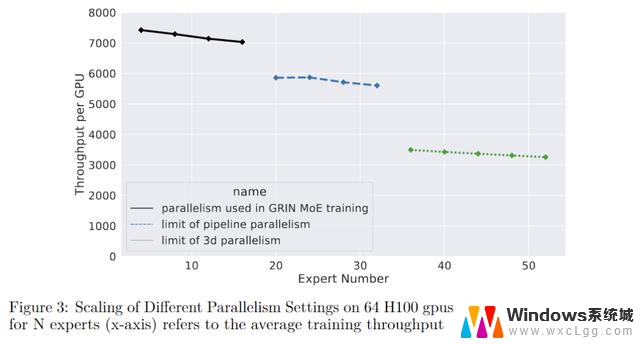
如上图所示,通过结合pipeline并行和张量并行,系统支持的最大专家数量扩展到52个(总共132B参数)。
这个数量是因为实验只用了64个GPU,最多能将模型划分为64个阶段,如果有更多的GPU,那么还能继续向上扩展。
不过作者也表示,使用更复杂的并行通常会导致计算吞吐量降低。
负载均衡
如前所述,本文没有采用专家并行,但是负载不均衡的事实依然存在。
作者在这里通过调整负载均衡损失来调节全局的负载均衡。常见的负载均衡损失定义为:
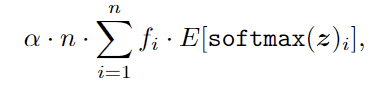
其中α是超参数,n是专家数量,fi是调度给专家的token比例。
传统方法在本地不同的GPU上计算fi,因此负载均衡损失将调节本地专家负载均衡并缓解token丢弃。
在本文中,作者通过计算全局的fi(比如数据并行过程中组内的all-reduce)来修改负载均衡损失,调节专家负载以达到全局平衡。
尽管这种调整会产生额外的通信开销,但类似于张量并行,这些通信也可以与计算overlap,从而在很大程度上减少额外的延迟。
最后,放一个测试结果来show一下GRIN MoE的数学推理能力:
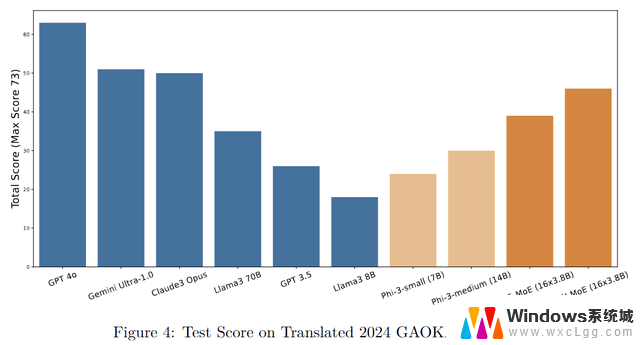
作者注:我们对新发布的GAOKAO(即全国普通大学和学院入学统一考试)的数学问题进行案例研究,这是中国一年一度的全国本科入学考试。
该考试以其严格的安全协议而闻名,是评估AI模型回答数学问题的能力的理想测试平台。请注意,GRIN MoE的训练于太平洋标准时间6月3日结束,2024年GAOKAO于中国标准时间6月7日开始。
专家模型不要专家并行!微软开源MoE新路径,颠覆传统机器学习模式相关教程
-
 微软欲甩掉OpenAI?千块GPU专训小模型启动必应内测
微软欲甩掉OpenAI?千块GPU专训小模型启动必应内测2023-09-27
-
 苹果Vision Pro颠覆机上娱乐体验,微软Word负责人分享使用感受
苹果Vision Pro颠覆机上娱乐体验,微软Word负责人分享使用感受2024-02-13
-

-
 微软新款Xbox掌机原型曝光,不是云掌机,真要杀入掌机市场!
微软新款Xbox掌机原型曝光,不是云掌机,真要杀入掌机市场!2024-03-24
-
 英伟达的颠覆式创新:芯片行业迎来30年来的新王者
英伟达的颠覆式创新:芯片行业迎来30年来的新王者2024-01-22
-
 两个小模型互相验证,直接比肩大模型?微软的rStar甚至没用CoT最新研究
两个小模型互相验证,直接比肩大模型?微软的rStar甚至没用CoT最新研究2024-08-16
- 微软开发出一种可在CPU上运行的超高效AI模型,革新人工智能技术领域
- 微软宣布大规模裁员,COD工作室遭到重击,玩家欢庆喜讯
- 微软推出小模型 Phi-2,性能优于 Llama 2/Mistral 7B,助力技术创新!
- 只有27亿参数,微软发布全新Phi-2模型!这是真的吗?揭秘真相!
- 微星GeForce RTX 5060Ti 16G硬派师评测:适合ITX小机箱的无光百搭显卡
- 影驰GeForce RTX 5060 Ti 金属大师黑金版MAX OC显卡开箱:2K光追游戏好手必备
- NVIDIA对一些中国客户隐瞒了美国新一轮芯片限制措施,行业内震惊!
- AMD苏姿丰:美国逐渐成为台湾供应链的关键一环
- 怎么样校验Win10 ISO的SHA1 如何验证MD5值?教你轻松验证Win10 ISO文件的完整性
- 科技巨头被指规避2780亿美元企业所得税,调查揭露苹果、微软等六大公司涉嫌避税风波
微软资讯推荐
- 1 微星GeForce RTX 5060Ti 16G硬派师评测:适合ITX小机箱的无光百搭显卡
- 2 影驰GeForce RTX 5060 Ti 金属大师黑金版MAX OC显卡开箱:2K光追游戏好手必备
- 3 微软开发出一种可在CPU上运行的超高效AI模型,革新人工智能技术领域
- 4 NVIDIA对一些中国客户隐瞒了美国新一轮芯片限制措施,行业内震惊!
- 5 AMD苏姿丰:美国逐渐成为台湾供应链的关键一环
- 6 怎么样校验Win10 ISO的SHA1 如何验证MD5值?教你轻松验证Win10 ISO文件的完整性
- 7 科技巨头被指规避2780亿美元企业所得税,调查揭露苹果、微软等六大公司涉嫌避税风波
- 8 AMD首款2nm芯片EPYC“Venice”采用台积电N2节点制造,性能提升明显
- 9 如何激活Windows系统,轻松解决电脑激活问题-最全攻略
- 10 如何安全有效地进行CPU超频教程与技巧,轻松提升电脑性能
win10系统推荐
系统教程推荐
- 1 笔记本开机闪屏是什么原因,怎么解决 笔记本电脑频繁闪屏怎么办
- 2 win10怎么更改子网掩码 Win10更改子网掩码步骤
- 3 声卡为啥没有声音 win10声卡驱动正常但无法播放声音怎么办
- 4 固态硬盘装进去电脑没有显示怎么办 电脑新增固态硬盘无法显示怎么办
- 5 word如何加批注 Word如何插入批注
- 6 怎么让word显示两页并排 Word文档同屏显示两页
- 7 win11直接改文件后缀 win11文件后缀修改教程
- 8 win11怎么查看电脑的物理地址 电脑物理地址查询方法
- 9 switch手柄对应键盘键位 手柄按键对应键盘键位图
- 10 win11安装共享打印机提示0000709 win11共享打印机提示0000709问题解决方法